Developing Machine Learning Applications
- AWS SageMaker
- AWS SageMaker Neo
- Machine Learning Algorithms
- Automatic Model Tuning
- Advanced Analytics with Amazon SageMaker
- Anomaly Detection on AWS
- Building Recommendation Systems with MXNet and GluOn
AWS SageMaker
AWS SageMaker is a fully managed service that allows the users to build, train and deploy machine learning models.
Underlying steps are fully managed by AWS through each of the stages:
- Build
- Easily and quickly setup Jupyter Notebook instance
- Train
- Distributed training environment
- Spinning up a cluster of instances
- Loading Docker container which has an algorithm
- Bring in data from S3
- Train the algorithms
- Output data back to S3
- Tear-Down the cluster
- Allows you to use custom-build algorithm and bring in your own Docker container
- Tune
- Deploy
Notebook Instance
- Jupyter Notebooks
- Open-source web application that allows users to author and execute code interactively
- Widely used by the data scientists community
- Can use any of AWS built-in models
- Docker image can be provided for endpoint deployment
AWS SageMaker Neo
Challenges Faced
- Framework
- Choose a framework best-suited for the task at hand
- Models
- Build the models using the chosen framework
- Train
- Train a mdoel using sample data to make accurate predictions on bigger data sets
- Integrate
- Integrate the model with the application
- Deploy
- Deploy the application, the model and the framework on a platform
AWS SageMaker Neo
- Helps developers take models trained in any framework and port them to any platform
- Converts model from Framework-specific format to portable code
- Optimizes the framework to run up to 2 times faster and 100x memory footprint reduction
- Supports populat deep learning and decision tree models
- Apache MXNet, TensorFlow, PyTorch and XGBoost
- Various EC2 instances and edge devices
AWS SageMaker Neo Components
- Neo Compiler Container
- Takes the framework-specific model as an input
- Converts to framework-agnostic representation
- Optimzes the model performance
- Reduces the model’s runtime footprint
- Shared Object Library
Machine Learning Algorithms
Machine Intelligence
- Knowledge Acquisition
- Inductive Reasoning
- Coming up with rules which would explain the observations
- Inference
- Ability to use acquired knowledge to derive truths
- Deductive Reasoning
- Predictions
Predicting Numbers
- Regression Problem
Linear Supervised Algorithms
- Linear decision boundary
- Hyperplane that best separates samples belonging to different classes
- Linearly separable classes
- If there exists a linear surface that separates 2 classses
- Error margin is expected in real-life situation
- Support Vector Machine (SVM)
- Perceptron
- AWS SageMaker Linear Learner
- Linear + Logstic Regression
Non-Linear Supervised Algorithms
- Decision Tree
- RandomForest, XGBoost are based on these approaches
- Factorization Machines
- Good for high dimensional sparse datasets
- Click prediction & item recommendation
- Polynomial
- Neural Networks
- AWS SageMaker supports XGBoost - Gradient Boosted Trees
Unsupervised Learning Algorithms
- Clustering
- Given a collection of data points trying to divide the samples into clusters
- Assume that points belonging to the same cluster are somehow similar
- Number of clusters should be specified
- Different Algorithms and Hyperparameters will lead to different clusters
- What do clusters represent? (will need to be defined after running the algorithm)
- Anomaly Detection
- Random Cut Forest
- Topic Modelling
- Given collection of documents and number of topics to discover
- Algorithm produces top words appearing to define a topic
- AWS
- SageMaker Supports K-Means Clustering
- Principal Component Analysis (PCA)
- Reduces dimensionality within a dataset
- Precursor to Supervised Learning
- Latent Dirichlet Allocation (LDA)
- Used for Topic Modelling by AWS Comprehend
- Anomaly Detection
- Kinesis Data Analytics
- Amazon SageMaker
- Hot Spot Detection
- Helps identify relatively dense regions in your data
- Supported Kinesis Data Analytics
Deep Learning
- Neural Networks
- Neuron
- Back-propagation Algorithm
Factors in Advent of Deep Learning
- Algorithms
- Data
- Programming Models
- GPUs & Acceleration
Deep Neural Networks
- Image understanding
- Natural Language Processing
- Speech Recognition
- Autonomy
Networks with over thousand layers have been experimented with
- Training can be distributed across several instances
- AWS provides GPU powered instances on-demand
AWS SageMaker
- DeepAR Forecasting
- Time Series Prediction
Convolutional Neural Networks (CNNs)
- Breakthrough in deep learning
- Especially useful for image processing
- Able to corelated nearby pixels in an image instead of treating as completely independent input
- Convolution operation is applied to subsection of the image
- Use Cases
- Object recognition, Image classification
- Semantic segmenetation
- Artistic style transfer
- Meow generator
- AWS SageMaker
- Image Classification (ResNet CNN)
Recurrent Neural Networks (RNNs)
- Output of a Neuron is feeded to the Neuron itself
- Long Short-Term Memory (LSTM Network)
- AWS SageMaker
- Sequence to Sequence (seq2seq)
- RNN for text-summarization, translation, TTS
- Sequence to Sequence (seq2seq)

Automatic Model Tuning
- Wraps up tuning jobs
- Works with custom algorithms or pre-built learning algorithms
- Helps find the best hyperparameters
- Improves performance of the machine learning model
Hyperparameters
- Help tuning Machine Learning Model to get the best performance
- Have large influence on performance of ML Model
- Grows exponentially
- Non-linear / interact
- Expensive Evaluations
Neural Networks
- Learning Rate
- Layers
- Regularization
- Drop-out
Trees
- Number
- Depth
- Boosting step size
Clustering
- Number
- Initialization
- Pre-processing
Tuning Hyperparameters
Manual
- Defaults, guess and check
- Experience, intuition, and heuristics
Brute Force
- Grid
- We try out each possibility of hyperparameter values and compare based on this
- Random
- Randomly pick values for each of the hyperparameters
- Sobol
Meta model
- Builds another ML model on top of your ML model
- Objective to predict which hyperparameters which yield the best potential accuracy
SageMaker’s method
- Gaussian process regression models objective metric as a function of hyperparameters
- Assumes smoothness
- Low data
- Confidence estimates
- Bayesian optimization decides where to search next
- Explore and exploit
- Gradient free
SageMaker Integration
- Accepts SageMaker algorithms
- Frameworks
- Your own algorithm in a docker container
Flat Hyperparameters
- Continuous
- Integer
- Categorical
Advanced Analytics with Amazon SageMaker
Building and Training Machine Learning Models with Amazon SageMaker and Apache Spark
Apache Spark
- Powerful data processing tool
- Rich ecosystem
- Distributed processing
Spark and SageMaker Integration
- Spark runs locally on SageMaker notebooks
- The SageMaker-Spark SDK
- Scala and Python SDK
- Amazon SageMaker algorithms are compatible with Spark MLLib
- There are Spark and Amazon SageMaker hybrid pipelines
- Connect a SageMaker notebook to a Spark Cluster (e.g. Amazon EMR)
Spark / SageMaker Integration Components
- Spark DataFrame
- Is a distributed data combined from different data sources
- Estimator
- Algorithm to use
- Parameters associated with the algorithm
- Types / Number of instances to host your model
- Model
- Training data is used to create a Model
- Model created
Building Machine Learning Pipelines using Spark and SageMaker
Problem: Recognizing handwritten numbers 0-9 using MNIST data set.
In this example Apache Spark will pre-process data to do feature reduction using PCA (Principal Component Analysis). We instantiate PCA object proving the input: set of Features, and a target number of features k. PCA algorithm will choose the most significant features and return “Projected Features”. Those features will act as an input to the second stage in the pipeline.
Defining the pipeline in Jupyter Notebook using both Spark SDK and SageMaker SDK will allow us to automate the process of pre-processing, training and deploying the model.
As a result we expect to have 2 Endpoints running on AWS SageMaker Infrastructure:
- Endpoint (PCA)
- Endpoint (K-Means)
This allows to fully de-couple the pre-processing task from prediction. On calling transform() function the Pipeline will first contact PCA Endpoint to reduce the features of the provided input and then will call K-Means Endpoint to get the prediction based on the Projected Features as an input.
Our pipeline will consist of the following steps:
- Performing feature analysis/reduction on the input data set using PCA algorithm running on Apache Spark cluster
- SageMaker Job will be created for running PCA feature reduction
- Training on reduced feature data using K-Means algorith on AWS SageMaker
- SageMaker Job will be created and will run automatically on completion of Step 1
- Running Test-Data using the created AWS SageMaker Endpoint
Anomaly Detection on AWS
Random Cut Forest Algorithm
- Algorithm developed by AWS for Anomaly detection
- Improvement of an existing algorithm [“Isolation Forest”](/aws certified mls/2014/09/10/isolation-forest-algorithm.html)
- Published in ICML 2016
- Incorporated into AWS Kinesis Data Analytics and AWS SageMaker
How it works
- Choose a bounding box randomly
- Choose the bigger dimension
- Perform the random cut
- Keep doing until each point is isolated
- Building a tree of random cuts
- Repeat the steps above to result in several trees, i.e. the Forest
Dealing with Stream of Data
- Reservoir Sampling
- Maintain a random sample of 5 points in a stream Put first 5 observed data points in our sample buffer of size 5
- For each new point, decide whether to keep or discard it
- Flip a coin for each data point
- For the first data point, the probability of retaining the point is 50%
- For each new data point, it becomes less and less likely that the point will be retained
- Produce a Random Cut Forest, with each tree looking into its own subsample of the stream
- For each new point we have to calculate the insertion point in the tree
- Based on the insertion point in the tree we will have to perform displacements to accommodate the new point
- Average Displacement in Forest will represent Anomaly Score
Shingle
- Results can be improved using Shingling technique
- A single data point is replaced by a window of datas
- Shingle size will define the window size (e.g. 48 hours in the time axis)
Architecture
Kinesis Streams
- Data from the source can be streamed to Kinesis Streams
- Kinesis Analytics can process the data from Kinesis Streams and label the Anomaly Score
- Using Amazon Kinesis Firehose the data can be redirected to S3 for further processing
SageMakers
- Data from the source can be passed to SageMaker through S3
- After Training, Model will be deployed to the Endpoint
- Any new data can be checked for Anomaly using AWS Lambda function
Building Recommendation Systems with MXNet and GluOn
Collaborative Filtering
- User based recommenders
- Identifies a short list of other users who are “similar” to you and rated an item. Assumes the average of their rating as your rating.
- Item based recommenders
- Identifies a short list of other items who are “similar” to the item in question and take a weighted average of the ratings for those top few items which you provided and predict that number as your likely rating for that item.
Matrix Factorization
Factorizes a matrix to separate matrices, that when multiplied approximate to the completed matrix.
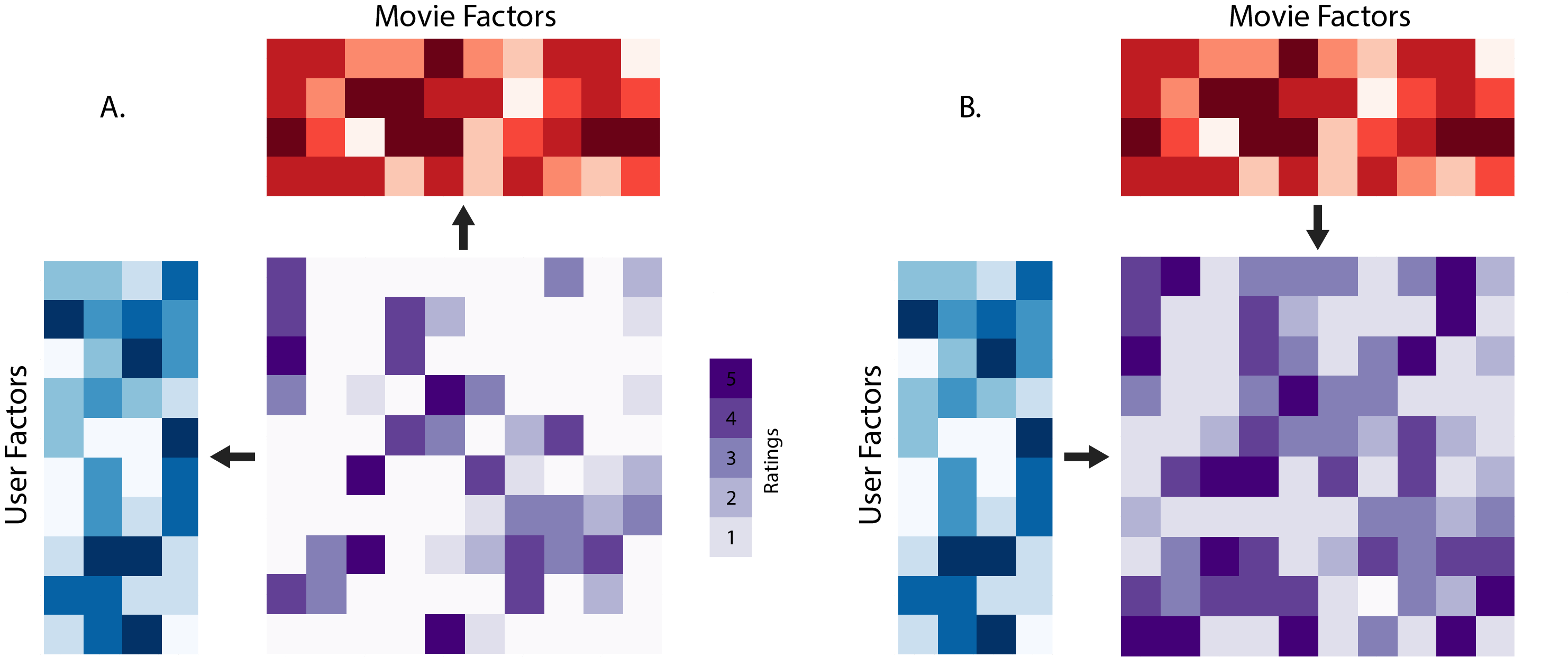
- Using GluOn Library
- MXNet with Linear Model
- MXNet with Non-Linear Model using Neural Network
- SageMaker
Points to Consider
- Matrix Factorization is ideal for small amounts of data
- Memory becomes a challenge with large data sets
- Factorization Machines and Distribution of the workload can help address the limitation and distribute the workload
Cold-Start Problem
- New users have no previous rating history
- New items have never been rated before
- Detecting similarity in items or users will help solve the Cold-Start Problem
- Content-based models
- Lot of information can be extracted from item/user
- Search criterias, click behavior, etc.. provide more data supply whenever the rating history is not available
Hybrid Models
- Combine item/user-based models with content based
Semantic Models
- Finding similarities based on Semantic of the data (movie titles, description, untapped data like images)
- Using Deep Structure Semantic Models (DSSM)
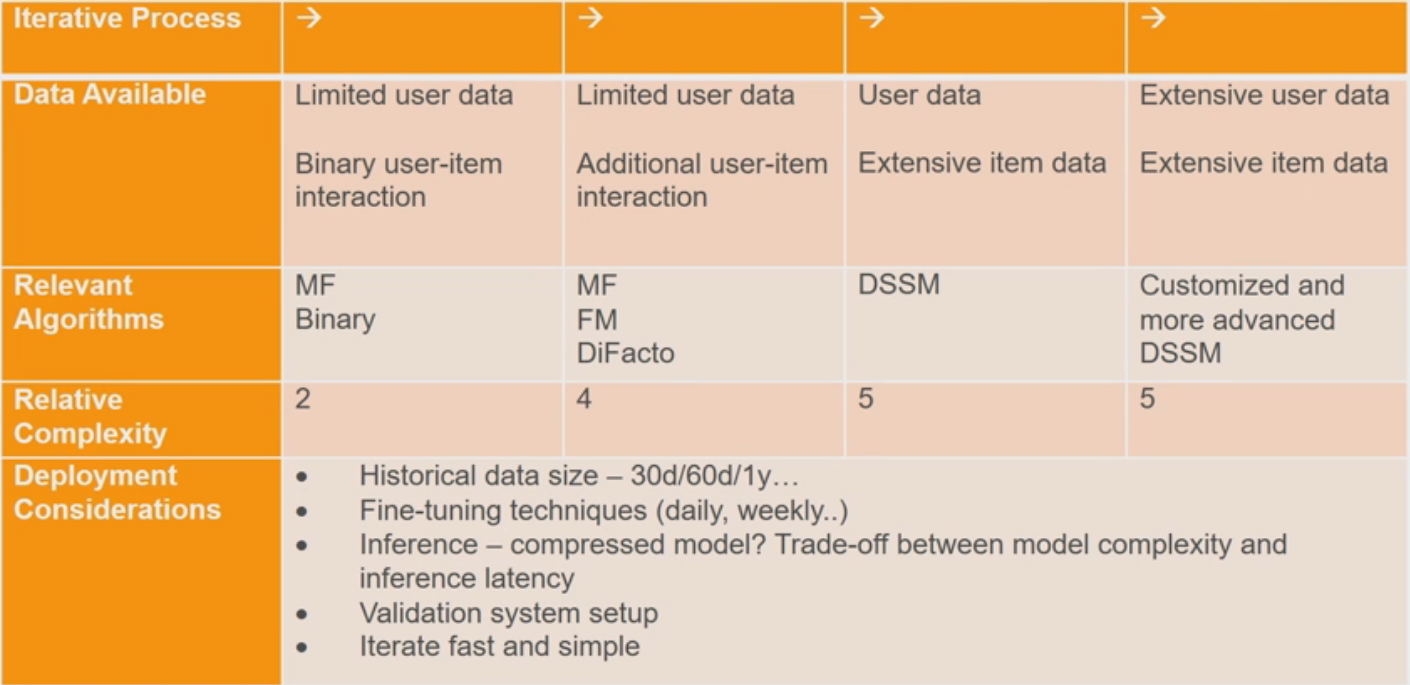
How to Choose a Model