Performance at Scale with Amazon ElastiCache
Overview
- ElastiCache deploys one or more cache clusters for your application
- ElastiCache automates resources provisioning, failure detection and recovery, and software patching
- Supports Redis and Memcached engines
Alternatives to ElastiCache
- Amazon CloudFront - cache images, web pages, static data at the edge
- Amazon RDS Read Replicas - distributing data to remote apps
- On-host caching - this approach lacks of efficiency - cannot reuse existing cache entries and maintain consistency in validation of the cache keys across all hosts
Memcached vs Redis
- Due to replication and persistence features of Redis, Redis is managed as relational database
- Memcached is designed as pure caching solution with no persistence - is managed as pool of nodes that can grow and shrink, similar to Amazon EC2 Auto Scaling Group
Important questions to consider impacting the choice of the caching engine:
Memcached:
- Object caching as a primary goal? Offload database?
- Simplest caching model?
- Large cached nodes, multi-threaded performance with utilization of multiple cores
- Scale cache horizontally?
- Atomically increment / decrement counters?
Redis
- More advanced types, e.g. lists, hashes, bit arrays, HyperLogLogs and sets?
- Sorting and ranking datasets in memory?
- Pub/Sub capabilities in your application?
- Persistence of the key store?
- Run in multiple AZs with failover?
- Geospatial support?
- Encryption and compliance standards? PCI DSS, HIPAA, FedRAMP?
ElastiCache for Memcached
- Considerably cheaper to add an in-memory cache then to scale up to a larger database cluster
- Easier to distribute an in-memory cache horizontally in comparison to relational database
- Choose the same AZs for ElastiCache as your application servers
- Specify Preferred Zones option during cache cluster creation
- Spread Nodes Across Zones tells ElastiCache to distribute nodes to AZs evenly
- Expect slightly higher latency for cross-zone AZ requests
Cache Node Size
- M5 or R5 families support the latest generation CPUs and networking capabilities
- Delivers up to 25Gbps of aggregate networking bandwidth with enhanced networking and over 600 GiB of memory
- M5.large single node can be a good starting point
- Track resource utilization through CloudWatch metrics
- Estimate the memory requirements by calculating the size consumed per cache item x number of items you want to cache
Security Groups and VPC
- ElastiCache supports security groups
- Advised to launch in a private subnet with no public connectivity
- Memcache doesn’t have any serious authentication or encryption capabilities
- Create a security group for ElastiCache cluster and allow traffic from “application tier” security group
- Test connectivity from an application instance to your cache cluster in VPC, using netcat:
nc -z w5 [cache endpoint] 11211
# will return 0 if connection was successful (the exist code of last command)
echo $?
Caching Design Patterns
Some questions you need to think of:
- Is it safe to use a cached value?
- Is caching effective for that data?
- Is the data structured well for caching?
Problem Overview Objective: Splitting cache keys across multiple nodes to make use of multiple ElastiCache nodes
- Naive approach is to randomly distribute cache keys
- Based on this approach hash key is generated from random CRC32
- Node corresponding to hash key % (modulo) number of nodes will contain the key
- In the event of scaling, you will have to remap some keys, i.e. old count / new count
- If Scaling from 9 to 10 nodes, you will have to remap 90% of your keys
- Bad approach as scaling the nodes introduces more load on the database
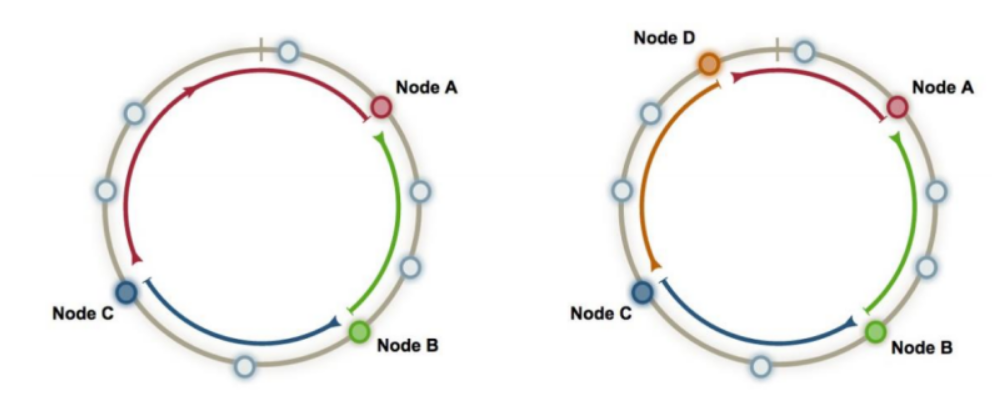
Consistent Caching (Sharding)
- Consistent Hashing
- Alternative approach to spreading cache keys across your cache nodes
- Creating internal ring with a pre-allocated number of partitions that can hold hash keys
- There’s mathematical calculation involved to preallocate a set of random integers and assign cache nodes to the random integers
- In this case you find the closest integer in the ring for a given cache key and use the associated cache node
- Many Client Libraries support consistent hashing
- Make sure that consistent hashing is enabled in the client library
- For example in PHP:
$memcached->setOption(Memcached::OPT_LIBKETAMA_COMPATIBLE, true);
- For example in PHP:
- If possible use ElastiCache Clients with Auto Discovery to support Auto Discovery of new nodes as they are added to the cluster
- Make sure that consistent hashing is enabled in the client library
Lazy Caching
- Populate the cache only when an object is requested by the application
- Cache only contains objects that application requests, keeping the cache size managable
- Cache expiration is easily handled by deleting the cached object
Write On Through
- Cache is updated realtime when the database is updated
- Advantages
- Avoids cache misses
- Shifts any application delay to the write operation, which maps better with user expectations
- Simplifies cache expiration (cache is always up to date)
- Disadvantages
- Cache may be filled with unnecessary objects and may evict more frequently accessed objects out of cache
- If cache node fails you need to apply lazy cache mechanism to populate the cache
Expiration Date
- Always apply TTL for all cache keys, except those updated by write-through caching
- For rapidly changing data add a TTL of few seconds to minimize the load on database
- Russian doll caching pattern: Nested records are managed with their own cache key and top-level resource is a collection of those cache keys
- When not sure, delete a cache key - Lazy Caching should refresh the key when needed
The Thundering Herd
- The Thundering Herd effect happens when high number of users request the same piece of data with a cache miss
- Usually happens in highly concurrent environment
- This effect can also happen when adding a new cache node - as it has an empty memory
- Possible Solutions
- Prewarm the cache using a script that hits a set of URLs
- Prewarming can be automated by triggering the script to run whenever the app receives a cluster reconfiguration event through Amazon SNS
- Add a bit of randomness to cache TTLs to mitigate simultaneous expiry event
ttl = 3600 + rand() * 120
- Prewarm the cache using a script that hits a set of URLs
Cache (Almost) Everything
- Caching should be applied for the heavy queries of database
- Consider caching other less heavy queries as well, whenever appropriate
- Monitor cache misses to determine the effectiveness of your cache
Elastic Cache for Redis
- Redis data structures cannot be sharded
- Redis ElastiCache clusters are always a single node
- Primary node can have one or more read replica
- Replication group consists of a primary and up to five read replicas
- Number of replicas attached will affect the performance of primary node
- One or two read replicas in a different Availability Zone are sufficient for availability
- With Multi-AZ enabled will automatically failover
- Primary Endpoint is a DNS name of current Redis primary node
- In event of failover Primary Endpoint will be updated to point to new node
- Supports persistence, backup and recovery
Distributing Reads and Writes
- Requires configuring the application to write to primary endpoint and read from read replicas endpoint
- Read workloads can be separated from write workloads
- Read Replicas may return data slightly out of date from the primary node
- There’s a short lag between the write operation to be reflected on the read replicas
Reading data from replica?
- Is the value being used only for display purposes?
- Is the value a cached value, for example a page fragment?
- Is the value being used on the screen where the user might have just edited it? - using outdated value will look like a bug
- Is the value being used for application logic? - using outdated value can be risky
- Are multiple processes using the value simultaneously, such as a lock or queue? - using outdated value can be risky
Mutli-AZ with Auto Failover
- AWS ElastiCache will detect a failure of the primary node and transfer the primary endpoint to point into failover instance
- Failover process can take several minutes
- All production systems should use multi-az with auto-failover
- In case of the failover, the read replica selected to be promoted may be slightly behind master
- Slight data loss may be expected in case of rapidly changing data
Sharding with Redis
- Simple keys and counters - support sharding
- Multidimensional sets, lists and hashes - don’t support sharding
- Redis client has to be configured to shard between redis clusters
- Horizontal sharding can be combined with split reads and writes
- Sharded masters and sharded replicas
- Designing the application to support read/write design in future you can add multiple clusters in future
Advanced Datasets with Redis
Game Leaderboards
- Redis sorted sets simultaneously guarantee both uniqueness and ordering of elements
- Commnads start with
Z, e.g.ZADD,ZRANGE,ZRANK - On insertion element is reranked and assigned a numeric position
Recommendation Engines
- Some recommendation algorithmns, e.g. Slope One, require in-memory access to every item ever rated before by anyone in the system
- Data should be loaded in the memory to run the algorithm
- Redis counters can be used to increment / decrement the number of likes or dislikes for a given item
- Redis hashes can be used to manitain a list of everyone who liked / disliked an item
- Open source projects like Recommendify and Recommendable use Redis this way
- Persistence can be used to move keep this data in Redis
INCR "item:89287:likes"
HSET "item:89287:ratings" "Susan" 1
INCR "item:89287:dislikes"
HSET "item:89287:ratings" "Tommy" -1
Chat and Messaging
- Provides lightweight pub/sub mechanism
- Well-suited to simple chat and messaging needs
- In-app messaging, real-time comment streams
- Use
PUBLISHandSUBSCRIBEcommands - Pub/sub messaging doesn’t get persisted to disk
- You will loose the data if the cache node fails
- Amazon SNS can be considered as a reliable alternative topic-based system
SUBSCRIBE "chat:15"
PUBLISH "chat:15" "How are you?"
UNSUBSCRIBE "chat:15"
Queues
- Redis lists can be used to hold items in a queue
- When process picks up an item, item is pushed to in-progress queue and then deleted when the work is done
Resqueopen source project (uses by Github) uses Redis as a queue.- Redis queue has certain advantages
- Very fast speed
- Once and only once delivery
- Guaranteed message orderding
- ElastiCache for Redis backup and recovery options should be configured with Queue persistence in mind
Client Libraries and Consistent Hashing
- Redis client libraries support most popular programming languages
- Redis libraries rarely support consistent hashing as advanced types cannot be horizontally sharded
- Redis cannot be horizontally scaled easily
- Redis can only scale up to a larger node size, because its data structures must reside in a single memory image in order to perform properly
Monitoring and Tuning
Monitoring Cache Efficiency
- Use CloudWatch Metrics
- Watch CPU Usage
- CPUUtilization
- EngineCPUUtilization
- Evictions
- Large number of evictions indicates that your cache is running out of space
- CacheMisses
- Large number of CacheMissed combined with large number of Evictions indicates that the cache is thrashing due to the lack of memory
- BytesUsedForCacheItems
- Indicates the total amount of memory used by Memcahced / Redis. Both try to use as much memory as possible.
- SwapUsage
- In normal usage, neither Redis nor Memcached should be performing swaps.
- Currconnections
- An increasing number of connections might indicate a problem with your application. This value can be used as a threshold for alarm.
- Scaling
- For read intensive workloads, consider adding read replicas
- For write intensive workloads, consider adding more shards to distribute the workloads
Watching for Hotspots
- Hotspots are nodes in your cache that receive higher load than other nodes
- Hotkeys - are cached keys that are access more frequently than others
- To investigate the hotspots is to track cache key access counts in application log
- Will significantly affect performance, so should not be done unless you are very suspicious of hotspots
- One possible solution is to create a mapping table to remap very hot keys to separate set of cache nodes
- Another is to add additional layer of smaller caches in front of your main nodes to act as a buffer - gives more flexibility but introduces additional latency
- Papers for researching on Hotspot issues:
- Relieving Hot Spots on the World Wide Web
- Characterizing Load Imbalance in Real-World Networked Caches
Memory Optimization
Memcached
- Uses slab allocator, allocates memory in fixed chunks
- When launching ElastiCache cluster,
max_cache_memoryparameter is set automatically chunk_sizeandchunk_size_growth_factorparameters work together to control how memory chunks are allocated
Redis
- Redis exposes a number of Redis configuraiton variables that will affect how Redis balances CPU and memory
Redis Backup and Restore
- AWS automatically takes snapshots of your Redis Cluster and saves them to AWS S3
- Redis backups require more memory to be available for the background Redis backup process
- For production - enable Redis backup with minimum 7 days retention
Cluster Scaling and Auto Discovery
- AWS does not currently support auto-scaling
- Number of cluster nodes can be changed from AWS console/API
- During changing the cluster nodes, some of the cache keys will be remapped to new nodes - impacting performance of your application
- ElastiCache clients support auto-discovery of Memcached nodes
- Auto-discovery enables your application to auto-locate and connect to the Memcached nodes
Cluster Reconfiguration Events from Amazon SNS
- Your application can be configured to dynamically detect nodes being added or removed by reacting to Events through SNS
ElastiCache:AddCacheNodeCompleteandElastiCache:RemoveCacheNodeCompleteevents are published when nodes are added and removed to the cluster- Follow the steps:
- Create AWS SNS topic for ElastiCache node additional and removal
- Modify application code to subscribe to the SNS topic
- When node is added or removed, re-run auto-discovery code to get the updated cache list
- Application adds the new list of cache nodes and reconfigured Memcached client accordingly